Introduction
How much time does your team lose every month fixing failed OIC runs caused by duplicate suppliers, missing employee data, or invalid codes?
More than you realize. Most of these failures occur due to poor data quality. Oracle Integration Cloud data cleaning is the process of identifying and correcting inaccurate, incomplete, or irrelevant records from your system.
Oracle Cloud data cleansing ensures accurate reporting, maintains compliance, and enables seamless integration between Oracle modules, helping your integrations run smoothly from the start.
Key Data Cleaning Techniques
Concept and Techniques of Imputation
Imputation techniques for enterprise data are critical for handling missing data by replacing null or blank values with estimated or representative ones. Instead of discarding incomplete records, imputation ensures that valuable information is retained for analysis and model training.
Common imputation techniques include:
- Mean/Median/Mode Imputation: Replaces missing numeric or categorical values with the mean, median, or mode of the respective attribute.
- K-Nearest Neighbors (KNN) Imputation: Uses values from similar records (neighbors) to fill missing fields.
- Regression Imputation: Predicts missing values using regression models based on other correlated features.
- Multiple Imputation: Generates several imputed datasets to account for uncertainty, then combines results for more robust estimates.
These techniques improve the accuracy and reliability of data pipelines, especially within Oracle Integration Cloud workflows, where clean and complete data ensures seamless integration and model accuracy. Handling missing data in Oracle Integration Cloud is essential for maintaining data integrity across all enterprise systems.
Key data cleaning techniques include handling missing values, removing duplicates, standardization, normalization, outlier detection, and validation. These techniques ensure consistency, accuracy, and trust in enterprise data used within Oracle applications.

Figure 1 illustrates the state of raw, inconsistent data before cleaning, compared to standardized and reliable data after cleaning. In the Oracle OIC context, this transformation ensures that downstream integrations receive only valid data, minimizing errors in ERP or HCM flows.
Data Cleaning Lifecycle
The data cleaning lifecycle in OIC follows clear stages that ensure reliability at every step.
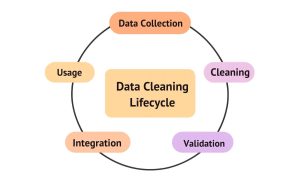
Figure 2 highlights the cycle of data collection, profiling, cleaning, validation, and deployment. In Oracle OIC, this means data is profiled and validated before integration, reducing downstream reconciliation efforts.
Integration with Oracle Cloud Applications
Data cleaning provides maximum benefit when integrated with Oracle’s core modules, including ERP, HCM, SCM, and CX.
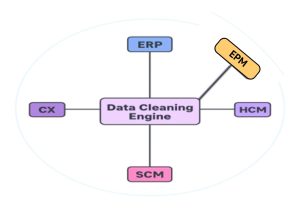
Figure 3 demonstrates how the central data cleaning engine connects seamlessly with ERP, HCM, SCM, and CX. This ensures each module shares consistent, validated data, enabling accurate reporting and end-to-end automation.
Data Quality Dimensions
Definitions of Data Quality Dimensions
- Accuracy: The degree to which data correctly describes the real-world entity or event it represents.
- Consistency: The uniformity of data across systems and datasets, ensuring that the same information does not conflict across sources.
- Completeness: The extent to which all required data is present, without missing or null values.
- Timeliness: How up-to-date the data is, ensuring it reflects the most current state of business operations.
- Validity: The adherence of data to defined business rules, formats, and constraints.
- Uniqueness: Ensures that each record is distinct, without duplication of entities.
Defining these dimensions helps organizations establish measurable data quality standards and enables ongoing monitoring within Oracle environments. Data validation in Oracle Cloud becomes straightforward when these dimensions are clearly defined and measured.
High-quality data can be measured across key dimensions such as accuracy, completeness, consistency, timeliness, validity, and uniqueness.
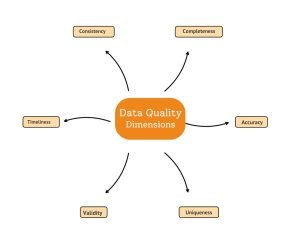
Figure 4 shows six pillars of data quality. In Oracle systems, ensuring these dimensions reduces redundant entries, missing employee details, or mismatched financial transactions, improving compliance and operational efficiency.
AI/ML Enablement through Clean Data
Clean data powers AI/ML enablement with clean data by reducing noise and ensuring accurate predictions.
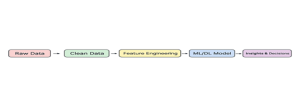
Figure 5 presents how clean data feeds into the AI/ML pipeline, ensuring robust feature engineering, reliable training, and accurate predictions. For Oracle OIC, this enables predictive analytics in supply chain, HR forecasting, and customer engagement.
Conclusion
Oracle customers should adopt systematic data cleaning strategies and leverage OIC features to ensure smooth integrations and accurate analytics. A roadmap that incorporates both technical best practices and organizational governance can maximize data value across all business functions.
| Area | Practice | Benefit |
| Data Entry Control | Enforce mandatory field validation for critical attributes (Supplier, Employee ID, Cost Center, BU) | Prevents incomplete or invalid records from entering the system |
| Duplicate Prevention | Apply uniqueness and duplicate detection rules | Eliminates duplicate suppliers, customers, and employees |
| Standardization | Maintain common naming conventions and code formats across modules | Ensures consistency across ERP, HCM, SCM, and CX |
| Data Audits | Schedule periodic automated data quality audits | Identifies issues before they affect integrations |
| Pre-Integration Validation | Validate data in OIC before triggering downstream integrations | Reduces integration failures |
| Data Ownership | Assign data owners and stewards for master data domains | Improves accountability and faster resolution |
| Monitoring & Alerts | Enable OIC fault monitoring and alerts | Allows proactive issue handling |
| Reference Data Control | Maintain version-controlled LOVs and lookup tables | Prevents code mismatches |
| User Awareness | Train business users on data quality standards | Reduces data entry errors |

Harshi Jain is a skilled in OIC, VBCS, DSA, along with hands-on research experience at IIT Roorkee. She is passionate about building scalable solutions and solving complex technical challenges.
Beyond her technical work, Harshi has a deep interest in human psychology and non-verbal communication. She enjoys interacting with people, actively works on building her personal brand, and aspires to become an entrepreneur, blending technology, communication, and creativity to create meaningful impact.
Recent Posts





Categories
Latest News

Website Launch And 3 Lessons From Chandrayan-3
January 16, 2024


Real Time Visibility In Supply Chain
January 16, 2024