The Mars Curiosity Rover wasn’t just sent to Mars to collect data – it was built to explore questions no one could yet answer. It didn’t land there by chance either. It happened because thousands of people believed that discovering new things isn’t optional – it’s a responsibility.
Progress, after all, depends on a certain kind of thinking. The willingness to ask why, to challenge assumptions, and to keep pushing on what if long enough for patterns to emerge and insights to take shape.
Curiosity, in that sense, isn’t just a machine. It’s a mindset.
And yet, that mindset is often missing where it matters most – like during the appraisal season.
By the time the performance ratings are finalized, most organizations have shifted gears into execution mode. Reviews are written. Ratings are calibrated. Promotion recommendation decisions are lined up. The focus is shifted to rollout – getting everything published smoothly and on time.
But what if this window, right before the results go live, isn’t the end of the process – but for you to be Curious?
Curious as in taking a deliberate pause to interrogate outcomes. To ask – Why are certain teams rated consistently higher than others? Are you being reviewed on the performance, or just based on what was most recent or most visible?
Because the bitter truth is performance cycles don’t fail with a big bang; they fail quietly – through subtle errors and inconsistencies, subconscious assumptions, and patterns that will only emerge when someone is curious enough to look for them.
Here, we’ll make you uncomfortable by asking the harsh question:
Are you about to reward the bias?
To avoid this, we’ll discuss 3 key checks that will be worth running every single year before you hit publish:
Are you being paid your worth?
Let’s start with a question your compensation team almost certainly knows the answer to, but your HR Business Partner might not have on their radar.
Where do you actually sit in your salary band?
Not just your grades. Not just your title. But within the range itself – are you near the bottom, hovering around the middle, or nudging the top? That position has a name: compa-ratio. A ratio of 1.0 means you’re right at the midpoint of your band. Below 1.0, you’re in the lower half. Above it, the upper.
Now take that number and lay it next to your performance rating.
Two uncomfortable clusters tend to show up, and once you see them, you can’t unsee them.
The first is someone who’s been rated “Below Expectations” but is sitting at a compa-ratio of 1.15 or above. They’re being paid well above the midpoint of their band, and they’re not delivering the performance that justifies it. That’s a budget problem, yes, but it’s also quietly unfair to every colleague around them who’s working harder and earning less.
The second cluster is the one that should keep you up at night. Someone rated “Exceeds Expectations”, your best people, sitting at a compa-ratio below 0.85. They’re in the bottom quartile of their salary band despite delivering exceptional work. And here’s the thing: they usually know. They can feel it. If they haven’t started quietly exploring other options yet, the moment you publish this appraisal without addressing it, the clock starts ticking.

Neither of these is a rare case. They exist in almost every performance cycle, in almost every organization. They persist not because HR doesn’t care, but because nobody ran the cross-check before hitting publish.
So do it now, while you still can. Pull compa-ratio from compensation, lay it against your ratings, and look for these two clusters. What you choose to do with what you find is what separates a genuinely fair appraisal process from one that just looks like the part.
Is your manager rating fairly – or just consistently?
Here’s something nobody says out loud during performance calibration but probably should: every manager walks into that room convinced their ratings are fair.
And most of them genuinely believe it.
But there’s a difference between meaning well and rating fairly – and the gap between those two things only becomes visible when you zoom out and look at the numbers side by side.
So, ask yourself: how does each manager’s rating distribution actually compare to everyone else’s?
Picture this. Your company’s average for “Exceeds Expectations” sits at 18%. One manager has rated 55% of their team there. Now, is it possible they’ve somehow assembled the most exceptional group of people in the entire organization? Sure, it’s possible. But it’s worth asking the question, because what’s more likely is that this manager struggles to have difficult conversations, defaults to generous ratings to keep their team happy, and has quietly made “Exceeds” mean something very different on their floor than it does everywhere else.
The other end of the spectrum is just as damaging, just in a quieter way. A manager who rates 95% of their team as “Meets Expectations” – regardless of what actually happened that year, is essentially telling their strongest performers that outstanding work and average work look the same from where they’re sitting. That’s not just demoralizing. It’s the kind of thing that makes people update their LinkedIn profiles.
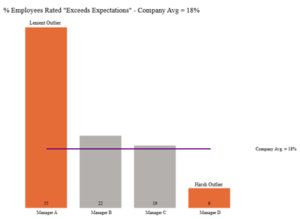
This isn’t a call to force everyone onto a bell curve. It’s simpler than that. Find the managers whose distributions are genuine outliers, sitting more than one standard deviation from the peer group average, and have a calibration conversation with them before the results go live.
Because once the appraisals are published, you’re no longer course-correcting. You’re managing the fallout.
Is the same performance worth less depending on who delivers it?
This one will make quite a few people uncomfortable, which is precisely why it needs to be asked.
Not across the whole organization, but look within the same job grade, same function, even control for tenure, and compare average performance ratings across gender. At the organization level, it becomes too broad.
Now look at these numbers.
If women at Grade 5 in your Sales function are consistently rated 0.3 points lower than men at the same grade, and that gap holds across multiple managers and multiple review cycles, that is a systemic signal. Not an anomaly. Not a coincidence. A pattern.

And here’s what makes this particular check so important – the bias is rarely intentional. Nobody sat down and decided to rate women lower. But as per McKinsey and LeanIn’s Women in the Workplace 2024 Report, for every 100 men promoted, there are only 81 women promoted, which is only 3 more than the women promoted as per the study in 2018. The ratings themselves were part of the problem, year after year, long before anyone noticed.
The window before appraisals go live is where you can actually do something about it. You still have room to course-correct, to go back to managers, to ask harder questions, and to fix what can be. Once the results are published, that window closes. What was a quiet pattern becomes an official record that shapes someone’s pay, their promotion trajectory, and their sense of whether this organization actually values them.
Summing Up
The organizations that answer these questions right don’t just run appraisal cycles. They investigate them.
They treat the gap between “ratings complete” and “results published” as a window for discovery, a chance to surface bias, test alignment, and ensure that what looks fair on the surface actually is fair underneath.
In other words, they do what Curiosity was built to do: They ask better questions before they accept the answers.
Good news is that your Oracle Fusion HCM Cloud already captures the data for every check we’ve discussed above – salary bands, performance review final ratings, legislative and demographic attributes. It’s just a matter of running those checks.
Oracle’s Workforce Compensation module can flag the mismatches in compa-ratio and performance ratings, the two danger zones – Overpaid Underachievers and Underpaid High Performers, to the managers even before they even submit their recommendations for promotions. Most implementations never configure these warning signs. They exist. They just sit unused.
One route to reduce leniency or severity bias is by switching the rating scales. Instead of letting the managers review on a 5-point scale, with a comfortable “Meets Expectations” where they can park 80% of their team, switch to a 4-point rating scale. Every rating given would be backed with deliberate thought. It involves a small configuration change, but the impact is significant. Furthermore, leveraging automated rating calculation can limit the scope for arbitrary or inconsistent scoring.
As per Harvard Business Review’s article How Gender Bias Corrupts Performance Reviews, and What to Do About It, the fix for gender bias starts with having 360-degree feedback. Oracle’s Performance Management is well-equipped to do this. It can be used to allow input from supervisors, matrix managers, and even peers, while check-ins can be set up for regular touchpoints throughout the year rather than a single end-of-cycle review. In addition to this, the performance rating scale can be fixed by using outcome-specific, gender-neutral criteria that evaluate what an employee did, not who their manager thinks they are.
And then there’s AI. An AI agent, in combination with your HCM data, will not wait for the HR or anyone else to ask these questions. It keeps monitoring, flagging managers whose ratings have drifted beyond one standard deviation from the peer group, shedding light on compa-ratio and ratings mismatch, running a check on gender bias using demographic attributes automatically. This may sound like a distant possibility, but this is what outcome-based tools like HindsightAI are already designed to do – to not let your data vanish into the dark before the window closes.
Curiosity was built to explore a planet about 140 million miles away, exploring and deriving actionable insights from your HCM data should be an easier problem to solve.

Recent Posts





Categories
Latest News

Website Launch And 3 Lessons From Chandrayan-3
January 16, 2024


Real Time Visibility In Supply Chain
January 16, 2024