
1. Introduction
When business processes change and transaction volumes rise, many Oracle Integration Cloud (OIC) systems struggle. A few years later, a scheduled integration that used to handle 8,000 records in less than 30 minutes can grow into a multi-hour operation without requiring significant code modifications. The integration itself may not have changed but the operating conditions have.
Creating a successful integration is rarely the difficult part. Building one that keeps functioning reliably as data quantities increase, source systems change, retries happen, and operational teams rely on it daily is the true difficulty.
2. Why Integration Quality Matters?
Performance issues are often visible, but data quality issues are usually more expensive.
A slow integration can delay processing. Inaccurate integration can create duplicate records, incomplete purchase orders, incorrect inventory positions, or reconciliation efforts that consume days of business and IT time. Successful integration teams treat these concerns as architectural responsibilities rather than post-production support problems.
The most common integration risks typically fall into three categories:
| Area | Typical Impact |
| Performance | Processing windows exceed operational limits |
| Reliability | Partial failures leave systems out of sync |
| Maintainability | Complex flows become difficult to support or enhance |
3. Designing Maintainable OIC Architectures
3.1 Avoid Monolithic Orchestrations
One of the most common production issues is the gradual growth of orchestration flow. Integrations often start simple but accumulate switch activities, exception scopes, scope specific logic, and custom workarounds over time.
While such integrations may remain functional, troubleshooting becomes increasingly difficult. Small schema changes or business rule updates can create unexpected failures in rarely tested branches.
A more sustainable approach is a parent-child integration model.
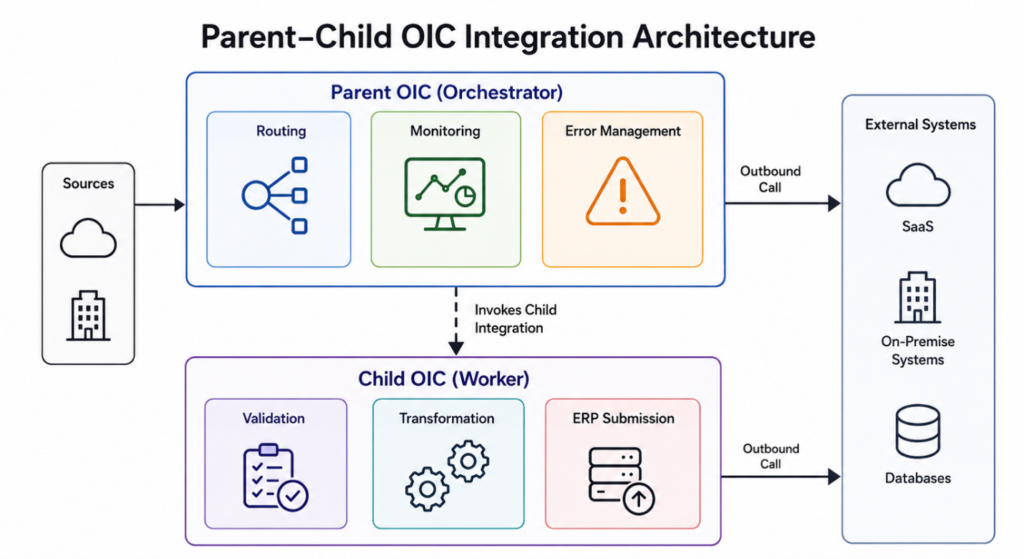
In this pattern:
- Parent integrations manage orchestration and tracking.
- Child integrations perform focused business functions.
- Failures are isolated more easily.
- Testing and deployment become simpler.
This approach improves governance, maintainability, and operational visibility.
4. Optimizing Large-Volume Processing
4.1 Choose the Right Processing Strategy
Many performance problems originate from scheduled integrations that retrieve large datasets and process records sequentially.
The most common anti-pattern is:
- Retrieve all records.
- Store them in memory.
- Execute one API call per record.
This works at small scale but becomes problematic as volumes increase.
For high-volume ERP transactions, Oracle’s bulk-loading mechanisms such as FBDI and HDL are generally better suited than record-by-record REST processing.
| Aspect | REST API Processing | FBDI Processing |
| Data Volume | Best for low to medium transaction volumes | Designed for high-volume bulk data loads |
| Processing Model | Real-time or near real-time processing | Asynchronous batch processing |
| Scalability | Limited by API rate limits and payload size constraints | Highly scalable and optimized for large datasets |
| Error Recovery | Requires custom retry and recovery logic | Provides batch-level error reporting and reprocessing capabilities |
| Operational Effort | Higher due to API orchestration, monitoring, and retry management | Lower for recurring bulk operations after initial setup |
Where bulk loaders are not applicable, pagination and batch processing should be used. Processing records in manageable chunks reduces memory consumption, simplifies recovery, and minimizes timeout risks.
4.2 A Less Discussed Scaling Challenge
Many teams focus on transaction volume while overlooking reference data lookups.
For example, an integration may process only 10,000 transactions but perform 50,000 validation calls against item categories, work centers, cost codes, or suppliers. These supporting lookups often become real bottlenecks.
Reference data that changes infrequently should be cached during execution or staged in a database for local access.
5. Reducing API Dependency and Runtime
5.1 Eliminate Redundant Lookups
A common production pattern involves validating multiple attributes for every transaction.
Consider a work order integration that validates:
- Work center
- Operation code
- Item master record
If each validation requires a separate ERP API call, processing overhead grows rapidly.
Instead:
- Retrieve reference data once.
- Store it in scope variables or staging tables.
- Perform local validation throughout the integration run.
This reduces unnecessary load on ERP services and improves execution consistency during peak periods.
6. Data Consistency and Idempotency
6.1 Preventing Silent Data Corruption
Some of the most expensive integration failures are not technical failures at all. The integration completes successfully, but the resulting data is incorrect.
Common examples include:
- Duplicate suppliers
- Duplicate customer records
- Missing purchase order lines
- Inconsistent inventory balances
Most of these problems occur because the system cannot reliably detect and ignore duplicate requests. Every create operation should be validated using a business identifier before insertion. Examples include:
- Supplier registration number
- Legacy item code
- Source-system purchase order number
- External work order reference
If the identifier already exists, the integration should update or skip processing rather than create a duplicate record.
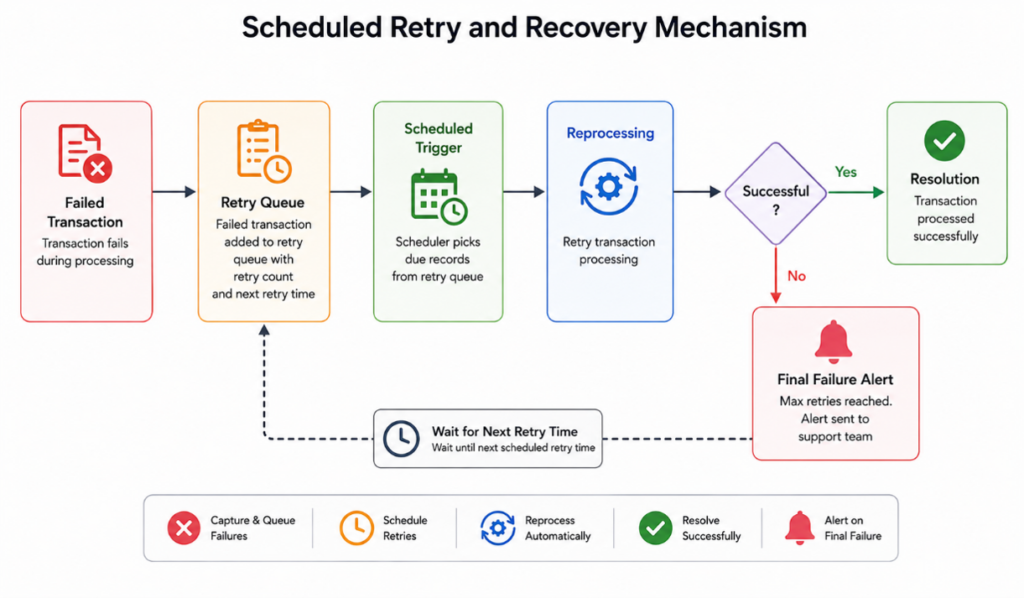
6.2 Building Recovery Mechanisms
Production environments inevitably experience partial failures. This pattern significantly reduces manual intervention and improves operational resilience.
Instead of relying solely on standard retries, implement a fault-tracking framework:
- Failed records are stored with payload and error details.
- Records receive a retry status.
- A scheduled integration attempts to reprocess.
- Persistent failures generate operational alerts.
7. Security and Configuration Management
Security weaknesses rarely appear as major incidents initially. Instead, they accumulate over time.
Common examples include:
- Hardcoded credentials
- Environment-specific URLs embedded in flows
- Sensitive payloads exposed in logs
- Stale passwords that have not been rotated
Production-grade integrations should use:
- Named credentials
- OIC Lookups for configuration
- Payload masking for sensitive information
- Centralized environment management
These controls improve security while simplifying deployment across environments.
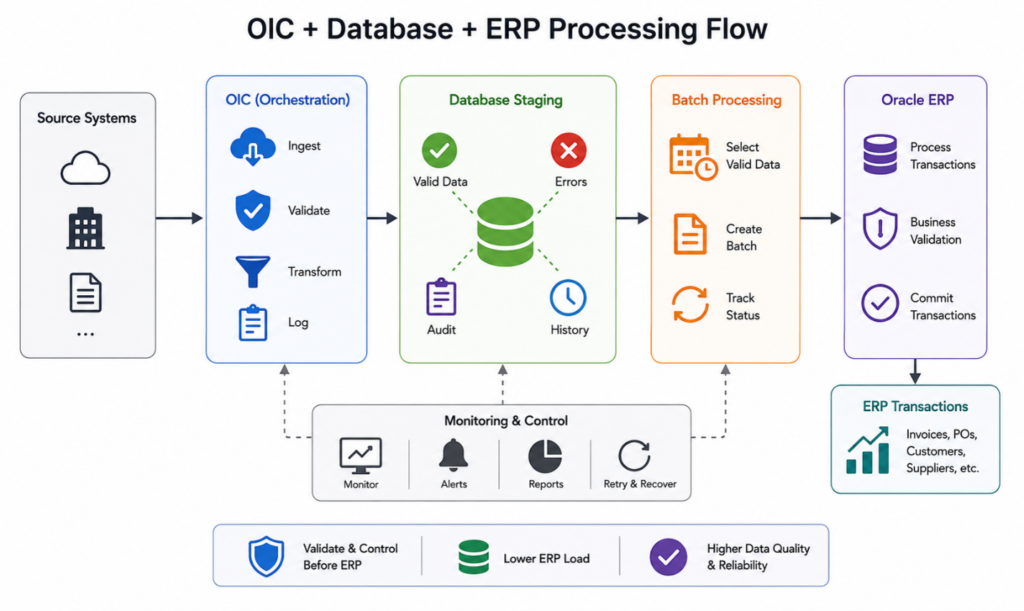
8. Leveraging Oracle Database and PL/SQL
Not every problem should be solved inside OIC.
Complex validations, bulk calculations, reconciliation routines, and mass updates are often better executed within Oracle Database.
A practical enterprise pattern is:
- OIC extracts source data.
- Data is staged in Oracle Database.
- PL/SQL performs validation and enrichment.
- OIC submits only validated transactions to ERP.
This division of responsibilities allows OIC to focus on orchestration while the database handles computation-intensive processing.
A frequently overlooked benefit is maintainability. Database logic can often be optimized independently without redesigning the integration flow itself.
9. Some Real-World Lessons from reported Production Environments
Several recurring patterns appear across enterprise implementations:
A retail organization reduced nightly item synchronization runtimes by replacing repeated validation of API calls with database-based validation and bulk import processing.
A procurement implementation eliminated duplicate supplier creation by introducing registration-number-based idempotency checks before ERP inserts.
A manufacturing client reduced recovery time for failed work-order transactions by implementing retry queues and automated alerting rather than relying on manual log reviews.
In each case, the solution was architectural rather than technical. The integrations already worked; they simply were not designed for long-term scale.
10. Checklist for scalable readiness of Production Environment
Before migrating an integration to production:
- Move calculation-heavy processing to PL/SQL when appropriate.
- Decompose overly complex orchestrations.
- Use FBDI or HDL for high-volume imports.
- Cache frequently used reference data.
- Implement idempotency checks for creating operations.
- Externalize all environment-specific configurations.
- Implement retry and fault-tracking mechanisms.
- Mask sensitive payload data.
- Configure meaningful business identifiers.
- Review monitoring dashboards regularly and treat rising fault rates as early warning indicators.
- Conclusion
True integration excellence isn’t achieved at go-live; it is sustained through continuous operational discipline and architectural foresight. By designing for future scale rather than current demand and building recovery mechanisms early, organizations ensure their integrations remain resilient long after initial deployment.
Also Read: The Complete Guide to Data Cleaning in Oracle Integration Cloud
11. Conclusion
True integration excellence isn’t achieved at go-live; it is sustained through continuous operational discipline and architectural foresight. By designing for future scale rather than current demand and building recovery mechanisms early, organizations ensure their integrations remain resilient long after initial deployment.